
When you interact with a webpage—clicking buttons, filling forms, or seeing dynamic content—you're witnessing the Document Object Model (DOM) API in action. The DOM is the bridge between your HTML and the JavaScript that makes your page interactive, but it can also be a major performance bottleneck if not used correctly.
Today, we'll explore how the DOM is structured, compare different ways to query elements, and learn performance-optimized strategies for DOM operations.
What Is the DOM?
The Document Object Model represents the HTML document as a tree structure where each node is an object representing a part of the document. The DOM API provides methods to programmatically access and manipulate this tree, allowing developers to change the document's structure, style, and content.
Global Objects and Class Hierarchy
Understanding the DOM's architecture helps you work with it more effectively. Here's a simplified view of the key objects and their relationships:
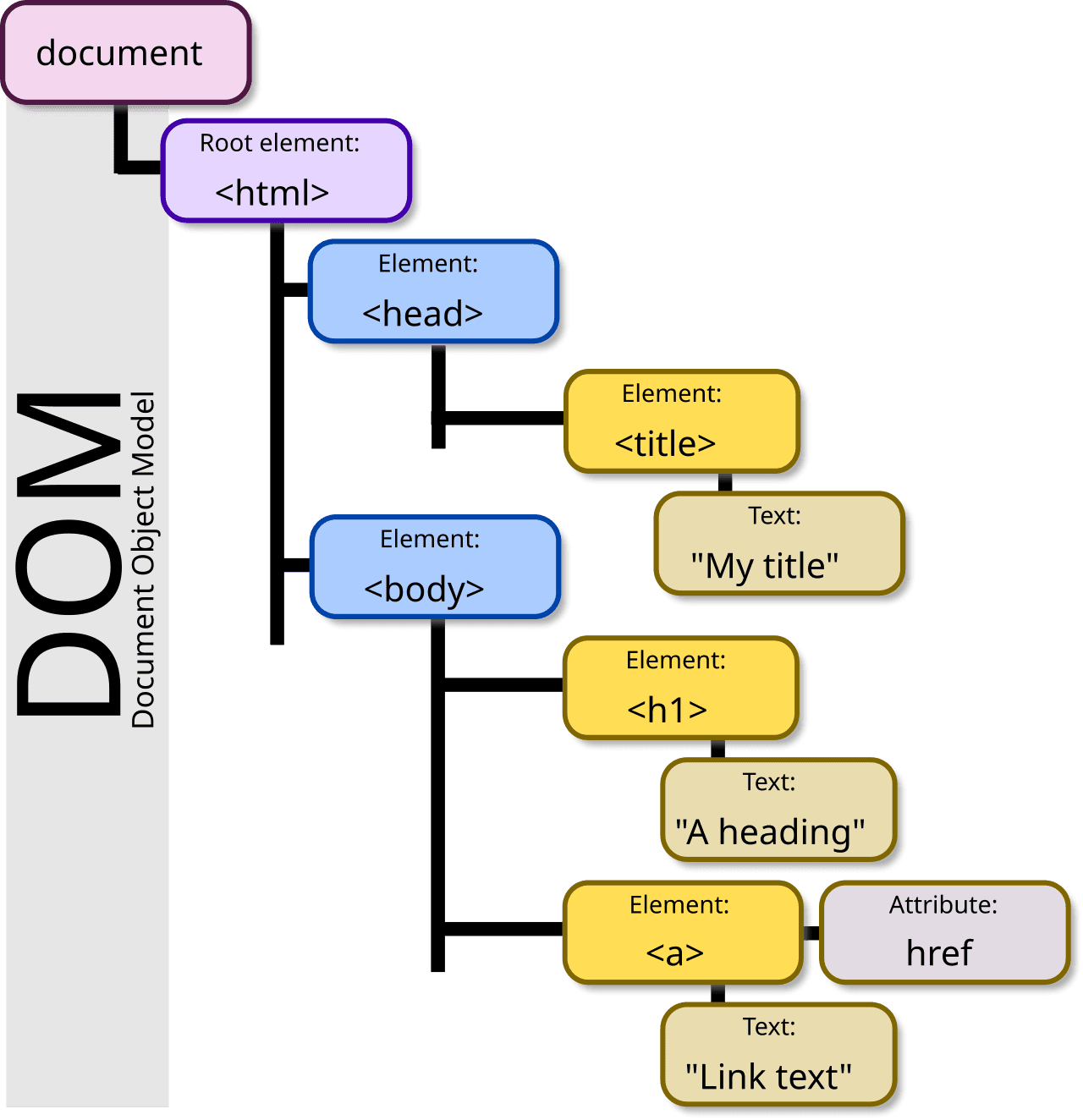
Key Global Objects
- Window: The global object that represents the browser window
- Document: Represents the entire HTML document
- Navigator: Contains information about the browser
- History: Provides methods to manipulate browser history
- Location: Contains information about the current URL
Class Hierarchy
The DOM operates on a class inheritance model, with each element type inheriting properties and methods from its parent classes:
- EventTarget: The base class that enables event handling
- Node: Inherits from EventTarget; represents a single node in the DOM tree
- Element: Inherits from Node; represents an element in the document
- HTMLElement: Inherits from Element; base class for all HTML elements
- Specific HTMLElements: Like HTMLDivElement, HTMLInputElement, etc.
// This is how the inheritance works:
EventTarget ← Node ← Element ← HTMLElement ← HTMLDivElement
// You can verify this in your browser console:
console.log(document.createElement('div') instanceof HTMLDivElement); // true
console.log(document.createElement('div') instanceof HTMLElement); // true
console.log(document.createElement('div') instanceof Element); // true
console.log(document.createElement('div') instanceof Node); // true
console.log(document.createElement('div') instanceof EventTarget); // true
Understanding this hierarchy helps you leverage common functionality. For example, all elements can dispatch events because they all inherit from EventTarget.
Querying Methods
The DOM API provides several methods to find elements in your document. Let's compare them:
getElementById
// Pseudo-browser code for getElementById
function getElementById(id) {
// Most browsers maintain an id-to-element map for direct lookup
return this.#idMap.get(id) || null;
// Older browsers without a map might do:
// return this.#documentTraversal({
// filter: node => node.id === id,
// findFirst: true
// });
}
Modern browsers optimize getElementById by maintaining a hash map where keys are IDs and values are direct references to elements. This is why the operation is O(1) regardless of document size.
querySelector
// Pseudo-browser code for querySelector
function querySelector(selector) {
// 1. Parse the selector into a structured representation
const parsedSelector = this.#parseCSSSelector(selector);
// 2. Start from rightmost part (key selector)
const keyPart = parsedSelector[parsedSelector.length - 1];
// 3. Find potential matches using the most efficient method
let candidates;
if (keyPart.id) {
candidates = [this.getElementById(keyPart.id)].filter(Boolean);
} else if (keyPart.className) {
candidates = this.getElementsByClassName(keyPart.className);
} else {
candidates = this.getElementsByTagName(keyPart.tagName || '*');
}
// 4. Filter candidates by testing against full selector
for (const candidate of candidates) {
if (this.#matchesCompleteSelector(candidate, parsedSelector)) {
return candidate;
}
}
return null;
}
This reveals why complex selectors are expensive:
- The selector must be parsed into a structured format
- The browser optimizes by starting with the rightmost/most specific part
- It gathers potential matches using the fastest applicable method
- It then tests each candidate against the complete selector
Performance Comparison
Let's see how these methods stack up in a real-world performance test:
// Assume a document with 1000 divs, 100 with class="item", and one with id="special"
// Test 1: getElementById
console.time('getElementById');
for (let i = 0; i < 10000; i++) {
const element = document.getElementById('special');
}
console.timeEnd('getElementById'); // Fastest: ~5-10ms
// Test 2: getElementsByClassName
console.time('getElementsByClassName');
for (let i = 0; i < 10000; i++) {
const elements = document.getElementsByClassName('item');
}
console.timeEnd('getElementsByClassName'); // ~20-50ms
// Test 3: querySelectorAll
console.time('querySelectorAll');
for (let i = 0; i < 10000; i++) {
const elements = document.querySelectorAll('.item');
}
console.timeEnd('querySelectorAll'); // Slowest: ~80-150ms
The Caching Effect
An interesting phenomenon occurs when you run query selectors repeatedly:
// First run
console.time('querySelector-first');
document.querySelector('div.complex > span.item[data-type="special"]');
console.timeEnd('querySelector-first'); // e.g., 3.2ms
// Second run
console.time('querySelector-second');
document.querySelector('div.complex > span.item[data-type="special"]');
console.timeEnd('querySelector-second'); // e.g., 0.4ms
Modern browsers optimize repeated selectors by caching results or selector parsing. However, this optimization varies across browsers and shouldn't be relied upon for critical performance needs.
Real-World Performance Implications
The performance differences become significant in these scenarios:
- High-frequency operations: In animations or scroll handlers
- Large DOMs: Pages with thousands of elements
- Mobile devices: Limited processing power makes inefficient queries more noticeable
Let's look at a common scenario: a table with dynamic filtering.
// ❌ BAD: Re-querying all cells on each filter change
function filterTable(keyword) {
const cells = document.querySelectorAll('td'); // Slow with large tables
cells.forEach(cell => {
if (cell.textContent.includes(keyword)) {
cell.classList.add('highlight');
} else {
cell.classList.remove('highlight');
}
});
}
// ✅ GOOD: Query once, reuse the results
let allCells; // Store reference
function initializeTable() {
allCells = document.querySelectorAll('td'); // Query just once
}
function filterTable(keyword) {
allCells.forEach(cell => {
if (cell.textContent.includes(keyword)) {
cell.classList.add('highlight');
} else {
cell.classList.remove('highlight');
}
});
}
initializeTable(); // Call on page load
Performance Best Practices for DOM Queries
Let's explore how to optimize your DOM interactions:
1. Be Specific with Your Selectors
// ❌ BAD: Overly broad, forces browser to check every element
document.querySelectorAll('div');
// ✅ GOOD: More specific, narrows the search space
document.querySelectorAll('#dashboard .widget');
2. Use the Right Method for the Job
// ❌ BAD: Using querySelectorAll for ID selection
const element = document.querySelectorAll('#uniqueId')[0];
// ✅ GOOD: Using the specialized, faster method
const element = document.getElementById('uniqueId');
3. Leverage Parenthood: Query from a Smaller Parent
// ❌ BAD: Searching the entire document
document.querySelectorAll('.list-item');
// ✅ GOOD: Limiting search to a specific container
const container = document.getElementById('main-list');
container.querySelectorAll('.list-item');
4. Cache DOM References for Repeated Access
// ❌ BAD: Re-querying on every event
document.getElementById('submit-button').addEventListener('click', () => {
const inputValue = document.getElementById('user-input').value;
document.getElementById('result').textContent = processData(inputValue);
});
// ✅ GOOD: Query once, reuse references
const submitButton = document.getElementById('submit-button');
const userInput = document.getElementById('user-input');
const resultElement = document.getElementById('result');
submitButton.addEventListener('click', () => {
resultElement.textContent = processData(userInput.value);
});
5. Use Structural IDs for Core Containers
<!-- Applying IDs to main structural elements -->
<div id="app-header">...</div>
<div id="main-content">...</div>
<div id="app-footer">...</div>
<script>
// Fast, direct access to key containers
const header = document.getElementById('app-header');
const content = document.getElementById('main-content');
const footer = document.getElementById('app-footer');
</script>
6. Prefer Class Manipulation for Visual Changes
// ❌ BAD: Using querySelector with every visual update
function updateStatus(isActive) {
const statusIndicator = document.querySelector('.user-card .status-indicator');
if (isActive) {
statusIndicator.style.backgroundColor = 'green';
statusIndicator.textContent = 'Active';
} else {
statusIndicator.style.backgroundColor = 'grey';
statusIndicator.textContent = 'Inactive';
}
}
// ✅ GOOD: Cache reference and use class toggling
const statusIndicator = document.querySelector('.user-card .status-indicator');
function updateStatus(isActive) {
statusIndicator.classList.toggle('active', isActive);
statusIndicator.textContent = isActive ? 'Active' : 'Inactive';
}
The Cost of Modifying the DOM
Beyond just querying elements, adding and removing DOM nodes has significant performance implications:
DOM Modification Performance Breakdown
- Insertions and Removals: Each insertion or removal triggers layout recalculations
- Batch vs. Individual: Batch operations are dramatically more efficient
- DOM Fragment Performance: Using document fragments reduces reflows
Let's see how these operations compare:
// Test: Adding 1000 items individually
console.time('individual-append');
const list = document.getElementById('list');
for (let i = 0; i < 1000; i++) {
const item = document.createElement('li');
item.textContent = `Item ${i}`;
list.appendChild(item); // Forces reflow on each iteration
}
console.timeEnd('individual-append'); // Slow: ~300-500ms
// Test: Adding 1000 items with a document fragment
console.time('fragment-append');
const list2 = document.getElementById('list2');
const fragment = document.createDocumentFragment();
for (let i = 0; i < 1000; i++) {
const item = document.createElement('li');
item.textContent = `Item ${i}`;
fragment.appendChild(item); // No reflow, everything stays off-DOM
}
list2.appendChild(fragment); // Only one reflow at the end
console.timeEnd('fragment-append'); // Fast: ~30-50ms
The fragment approach is typically 10x faster because it minimizes the number of reflows the browser must perform.
Element Creation vs. innerHTML vs. cloneNode
Another consideration is how you create new DOM elements:
// Test 1: createElement
console.time('createElement');
for (let i = 0; i < 1000; i++) {
const div = document.createElement('div');
div.className = 'test-item';
div.textContent = `Item ${i}`;
}
console.timeEnd('createElement'); // ~10-20ms
// Test 2: innerHTML
console.time('innerHTML');
let html = '';
for (let i = 0; i < 1000; i++) {
html += `<div class="test-item">Item ${i}</div>`;
}
const container = document.createElement('div');
container.innerHTML = html; // Browser must parse the string to DOM
console.timeEnd('innerHTML'); // ~30-50ms
// Test 3: cloneNode
console.time('cloneNode');
const template = document.createElement('div');
template.className = 'test-item';
for (let i = 0; i < 1000; i++) {
const clone = template.cloneNode(true);
clone.textContent = `Item ${i}`;
}
console.timeEnd('cloneNode'); // ~5-10ms (fastest)
For repeated creation of the same element type, cloneNode() is often the most efficient approach.
Advanced DOM Performance Techniques
1. Virtual DOM-like Approach
For complex updates, consider using a diffing approach to minimize actual DOM changes:
function updateList(newItems) {
const listElement = document.getElementById('item-list');
const currentItems = Array.from(listElement.children);
// Only update what's changed
newItems.forEach((item, index) => {
if (index >= currentItems.length) {
// Add new item
const li = document.createElement('li');
li.textContent = item;
listElement.appendChild(li);
} else if (currentItems[index].textContent !== item) {
// Update changed item
currentItems[index].textContent = item;
}
});
// Remove extra items if new list is shorter
while (listElement.children.length > newItems.length) {
listElement.removeChild(listElement.lastChild);
}
}
2. Virtualized Lists for Large Datasets
For very large lists, render only what's visible:
class VirtualizedList {
constructor(containerEl, itemHeight, createItemFn, totalItems) {
this.container = containerEl;
this.itemHeight = itemHeight;
this.createItem = createItemFn;
this.totalItems = totalItems;
this.visibleItems = [];
this.container.style.height = `${itemHeight * totalItems}px`;
this.container.style.position = 'relative';
this.container.style.overflow = 'auto';
this.container.addEventListener('scroll', this.onScroll.bind(this));
this.render();
}
onScroll() {
this.render();
}
render() {
const scrollTop = this.container.scrollTop;
const viewportHeight = this.container.clientHeight;
// Calculate visible range
const startIndex = Math.floor(scrollTop / this.itemHeight);
const endIndex = Math.min(
this.totalItems - 1,
Math.floor((scrollTop + viewportHeight) / this.itemHeight)
);
// Remove items that are no longer visible
this.visibleItems = this.visibleItems.filter(item => {
if (item.index < startIndex || item.index > endIndex) {
this.container.removeChild(item.element);
return false;
}
return true;
});
// Add newly visible items
for (let i = startIndex; i <= endIndex; i++) {
if (!this.visibleItems.some(item => item.index === i)) {
const element = this.createItem(i);
element.style.position = 'absolute';
element.style.top = `${i * this.itemHeight}px`;
element.style.width = '100%';
element.style.height = `${this.itemHeight}px`;
this.container.appendChild(element);
this.visibleItems.push({ index: i, element });
}
}
}
}
// Usage
const container = document.getElementById('large-list');
const virtualList = new VirtualizedList(
container,
50, // item height in pixels
(index) => {
const div = document.createElement('div');
div.textContent = `Item ${index}`;
div.className = 'list-item';
return div;
},
10000 // total items
);
This technique is similar to what libraries like React Virtualized implement, and it's essential for lists with thousands of items.
Monitoring DOM Performance
The Chrome DevTools Performance panel is invaluable for identifying DOM bottlenecks:
- Open DevTools (F12)
- Go to the Performance tab
- Click Record and interact with your page
- Stop recording and analyze the results
- Look for "Recalculate Style", "Layout", and "Update Layer Tree" events, which indicate DOM operations
Quick Recap
- DOM structure: The browser represents your HTML as a tree of objects
- Query methods:
getElementById,querySelector/All - Caching: Repeated query selector calls benefit from browser optimizations, but explicitly caching references is more reliable
- Best practices:
- Use specific selectors
- Query from closer parent elements
- Cache DOM references
- Use IDs for core containers
- Batch DOM modifications with fragments
- Consider
cloneNodefor repeated element creation - Implement virtualization for large lists
Conclusion
The DOM API is the interface between your code and what users see on screen. By understanding its performance characteristics and using the right methods for each task, you can build interfaces that respond instantly to user interactions, even on less powerful devices.
Remember: every DOM operation has a cost. The art of efficient DOM manipulation is minimizing the number of operations while keeping your code clean and maintainable.
In our next article, we'll explore Web APIs for complex UI patterns. Stay tuned!
Did you find this article helpful? Share it with your fellow developers on X or LinkedIn!